(2편)tensorflow, keras 내 맘대로 이미지 딥러닝![스마트인재개발원]
(1편)tensorflow, keras 내 맘대로 이미지 딥러닝![스마트인재개발원]
현재 교육을 듣고 있는 학원에 프로젝트에 딥러닝을 사용해야 하는 상황이 생겼고 대학교 4학년때 혼자 이상하게 모델을 학습하고 사용했던 기억을 되집어 보며 새로운 마음으로 이미지 딥러닝
rspring41.tistory.com
1편에 이어서 계속 진행 해보았다!!
마지막쯤에 예전에 사용했던 코드를 가져와서 오류가 나는 부분을 고치고 실행 해봤는데 간단한 CNN모델을 적용해서 학습 해보았는데 학습 그래프가 이상하다!!! 띠옹
1. 학습 결과 그래프가 이상해!
- 사용된 CNN층 구성도

- 학습 결과 그래프

위에서 학습 결과 그래프를 살펴보면 학습 데이터(train accy)는 파란색, 검증데이터(val acc)는 초록색으로 최종 학습률이 1 근처하고 0.7근처이다 대략 30%정도 차이나며 이렇게 큰 차이를 보이면 과적합되었다고 한다고 한다. 이걸 최소하 하기 위해서는 CNN 층에서 dropout층을 설정해줘야 한다고 한다
dropout층이란?

인공 신경망중에 일부 연결을 임의로 탈락시키는 방법이다. 이렇게 중간중간 탈락시키게 되면 overfitting을 방지 할 수 있다.
- dropout 적용 이후 학습 그래프

띠옹?.... 반응이 있기는 한데 뭔가 수상하다... 여전히 과적합을 보이고 있다!!
2. 과적합 이자식 이거이거 어떡하지?
인터넷 검색으로 나온 과적합 방지 방법들이다.
1. 데이터의 양을 늘리기
2. 모델의 복잡도 줄이기
3. 가중치 규제(Regularization) 적용하기
4. 드롭아웃(Dropout)
가장 쉬운 4번 방법을 사용해서 줄여 보았는데 뭔가 심상치 않다? 보통 인터넷에서 참고 할 수 있는 CNN모델들은 대부분 dropout층 포함 하고 있어서 이 해결법은 많이 사용되지 않을거 같다.
2. 데이터의 양을 늘려보자
데이터의 양을 늘린다는것은 사진을 좌우로 움직여보고 조금 회전 시켜보고 위아래로 뒤집어 보고 줌을 줬다가 줄여보고 등등 다양한 방식으로 이미지를 변형시켜 데이터 개수를 늘릴수 있다 이것을 '데이터증강'이라고 부른다.
- 사진 하나를 변형시켜 여러개에 사진으로 데이터를 늘렸다.

먼저 내 마음데로 딥러닝 1편에서 사용된 image_dataset_from_directory이라는 최상위 폴더를 기준으로 하위 폴더를 라벨로 잡고 내부에 있는 사진을 가져오는 기능이다.
1편에서 이 기능을 사용했던 이유는 예전에 사용했던 ImageDataGenerator기능과 flow_from_directory기능은 학습 데이터와 검증 데이터를 직접 따로따로 나눠줘야 해서 이번에는 seed와 validation_split속성을 이용해서 자동으로 나눌수 있기 때문에 사용했다. 하지만 이 기능은 '데이터 증강'기능이 없다... ㅠㅠ
증강 기능이 없다는걸 찾아보면서 image_dataset_from_directory와 flow_from_directory중 데이터 증강 기능이 있는 low_from_directory를 더 많이 사용한다는걸 알수 있었다.
low_from_directory에는 validation_split기능이 없나? 하고 엄청 찾아봤는데 keras 공식 홈페이지에서 flow_from_directory기능에 대한 설명중 validation_split이 떡하니 있는게 아닌가?
에휴.. 더 찾아볼껄... 그냥 예전에 이 기능을 몰라서 안썼던 거였다.....
그래서 자동 이미지 증강 기능을 이용해서 학습 해보았다!!
- 데이터를 증강시켜서 학습시킨 결과

뭔가 발전이 있다! 하지만 학습률이 이상하다... 왔다갔다 거리고 반복 횟수도 부족한거 같다.. 최종 검증 정확도는 74%!!
그래서 30회가 아닌 60회를 진행했다!!
- 60번 반복한 결과 그래프
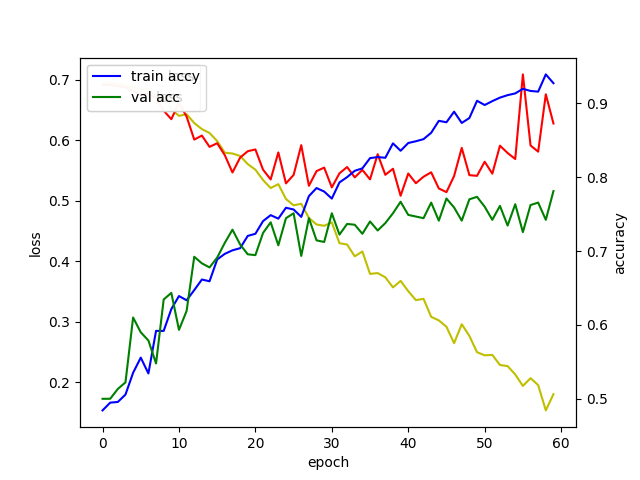
모양이 괜찮아 지기는 했는데 아직도 학습데이터는 95% 정확도, 검증데이터는 75% 정확도로 과적합이 일어났다.. 우우...
최종 검증 테이더 정확도는 79%!! 아직 부족하다!!
그리고 큰 문제가 생겼다..
flow_from_directory를 사용하면서 원래 사용하던 image_dataset_from_directory에 있는
# 데이터셋 사전 처리
AUTOTUNE = tf.data.experimental.AUTOTUNE
train_data = train_data.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_data = val_data.cache().prefetch(buffer_size=AUTOTUNE)를 사용할 수 없어 학습 시간이 2배가 되었다!! 젠장
그럼 남은 방법은 하나 모델을 최소화 해보자!!
이거는 다음 시간에!! 오늘 내용을 하려고 검색하고 적용 해보느라 너무 힘들다 흑흑

스마트인재개발원
4차산업혁명시대를 선도하는 빅데이터, 인공지능, 사물인터넷 전문 '0원' 취업연계교육기관
www.smhrd.or.kr